
 by
by I was talking to an account team VMware Datastore Clusters and their use with Storage DRS and a few questions came up.
A quick refresher will summarize that Storage DRS is used to move workloads from one datastore to another when events occur that change the characteristics of a vSphere Datastore Cluster. When I say events, I mean things like a performance threshold not being met, a vmfs datastore running out of capacity, or a vmfs datastore being put in maintenance mode.
The use case for Datastore Clusters
VMware vSphere 5.0 was released in August of 2012. Since that time datastores larger than 2TB have been supported by vSphere 5 and subsequent releases of vSphere.
As with any major upgrade, there are often some migration requirements, and going from vmfs3 to vmfs5 wasn’t necessarily an easy process. It is often easier to create new datastores, with a newer vmfs version, and migrating storage from an old datastore to a new datastore.
I’ve noticed over the last decade, that while vSphere supports larger datastores, many customers have been reluctant to create significantly larger datastores. 2TB and smaller datastores appear to be more common than one might think.
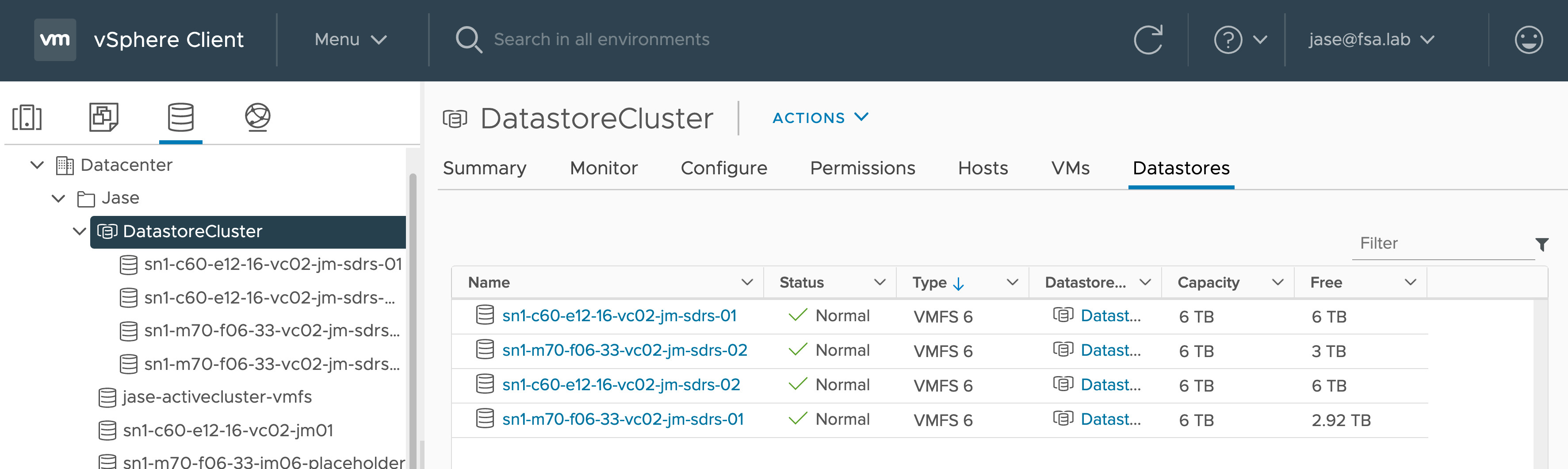
A Datastore Cluster is a collection of vmfs Datastores that are grouped together. By combining multiple 2TB Datastores in a Datastore Cluster, administrators have a larger target to deploy to, with some intelligence provided by Storage DRS to help with determining workload placement.
Enter Storage DRS
Storage Dynamic Resource Scheduling (Storage DRS) adds the ability to dynamically move virtual machines and their disks around when a Datastore is experiencing latency is becoming more full or is put into maintenance mode. Storage DRS also adds the ability to help with Datastore selection when deploying a workload. In a Datastore Cluster, Datastores with lower capacity utilization are typically selected when provisioning, rather than those with higher capacity utilization.
The runtime settings for a Datastore Cluster can be seen below: 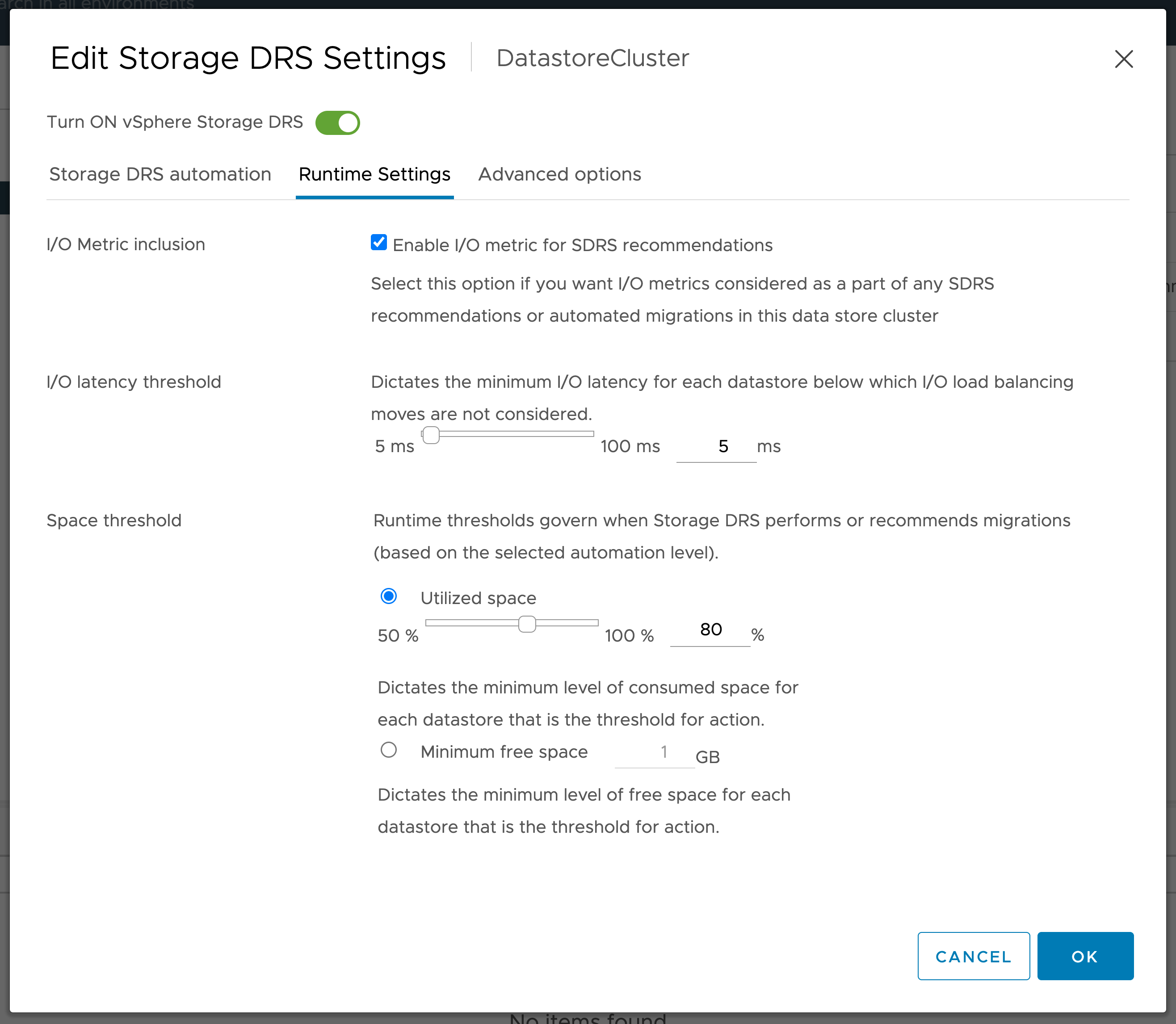 These runtime settings allow customers to modify the performance or capacity thresholds used when Storage DRS decides, either manually or automatically, where to place data.
These runtime settings allow customers to modify the performance or capacity thresholds used when Storage DRS decides, either manually or automatically, where to place data.
Performance-Based Inclusion/Thresholds
For customers using storage platforms that are not an all-flash architecture, such as hybrid or traditional spinning media types, it could be advantageous to use performance-based metrics to move data to faster-performing storage. This can often come at a cost, as the process of migrating a virtual machine can add to the performance overhead of the Datastore that is already experiencing latency.
However, for Pure Storage FlashArray //X and //C arrays, the lower end of the latency metric available (5ms) is below the typical latency these arrays provide FlashArray //X arrays typically provide <1ms latency and //C arrays typically provide between 2ms-4ms latency.
As a result, the typical guidance when using FlashArray is to uncheck I/O Metric Inclusion, as it isn’t necessary.
Capacity-Based Thresholds
It is more common with FlashArray to see customers using capacity-based thresholds to move data between Datastores residing on FlashArray when using Datastore Clusters. As a vmfs Datastore in a Datastore Cluster approaches its storage capacity, Storage DRS can move virtual machines and their disks to another Datastore in the Datastore Cluster to provide a more balanced distribution of space.
It is important however to understand that capacity utilization is only taken into account from a vSphere perspective, and not from the FlashArray perspective. Using the Pure Storage FlashArray Plugin for vSphere a more accurate depiction of storage utilization can be seen.
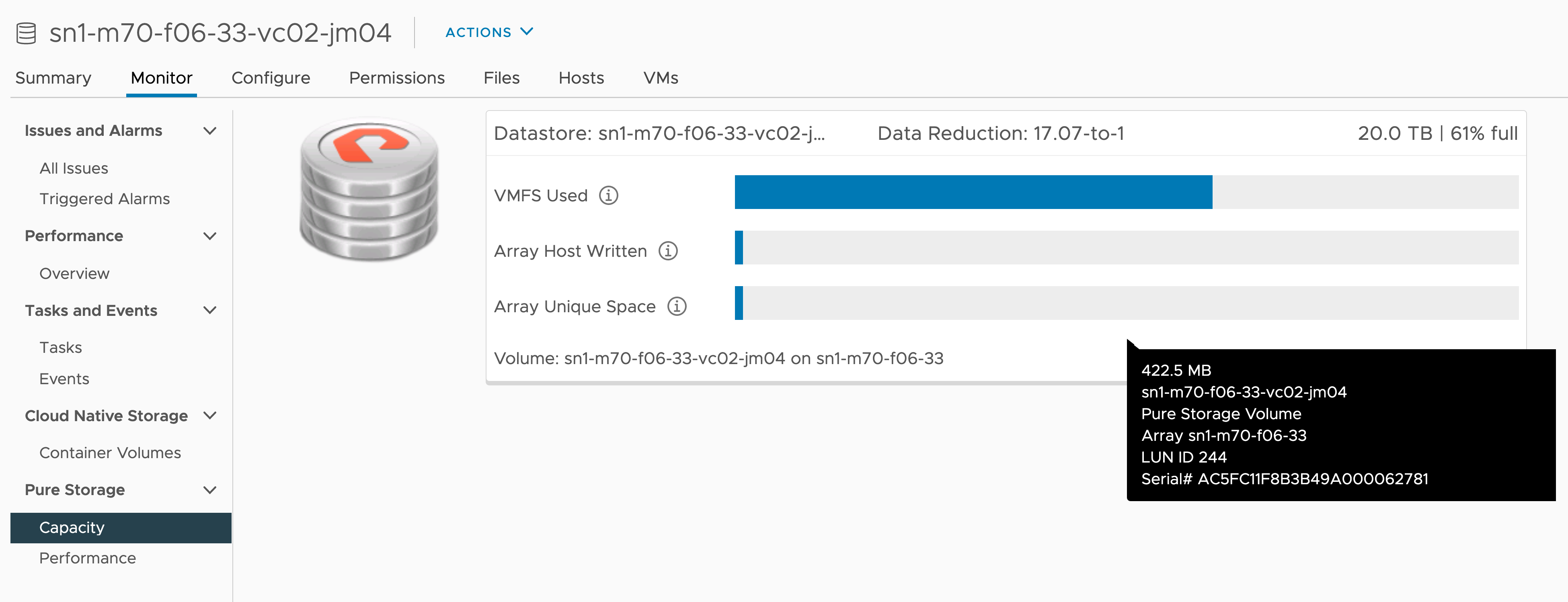
For Datastore Clusters that are comprised of Datastores from the same FlashArray, data doesn’t really “move” on the array side, rather pointers are updated as part of the XCOPY process with the VMware API for Array Integration (VAAI) Offload. The Storage vMotion process in this case is very fast.
For Datastore Clusters that are comprised of Datastores from different arrays (anyone’s array really), full data migration is required. This can be time-consuming, depending on multiple factors. These factors could include source/target array types/workloads, current I/O on the storage fabric/network, and more.
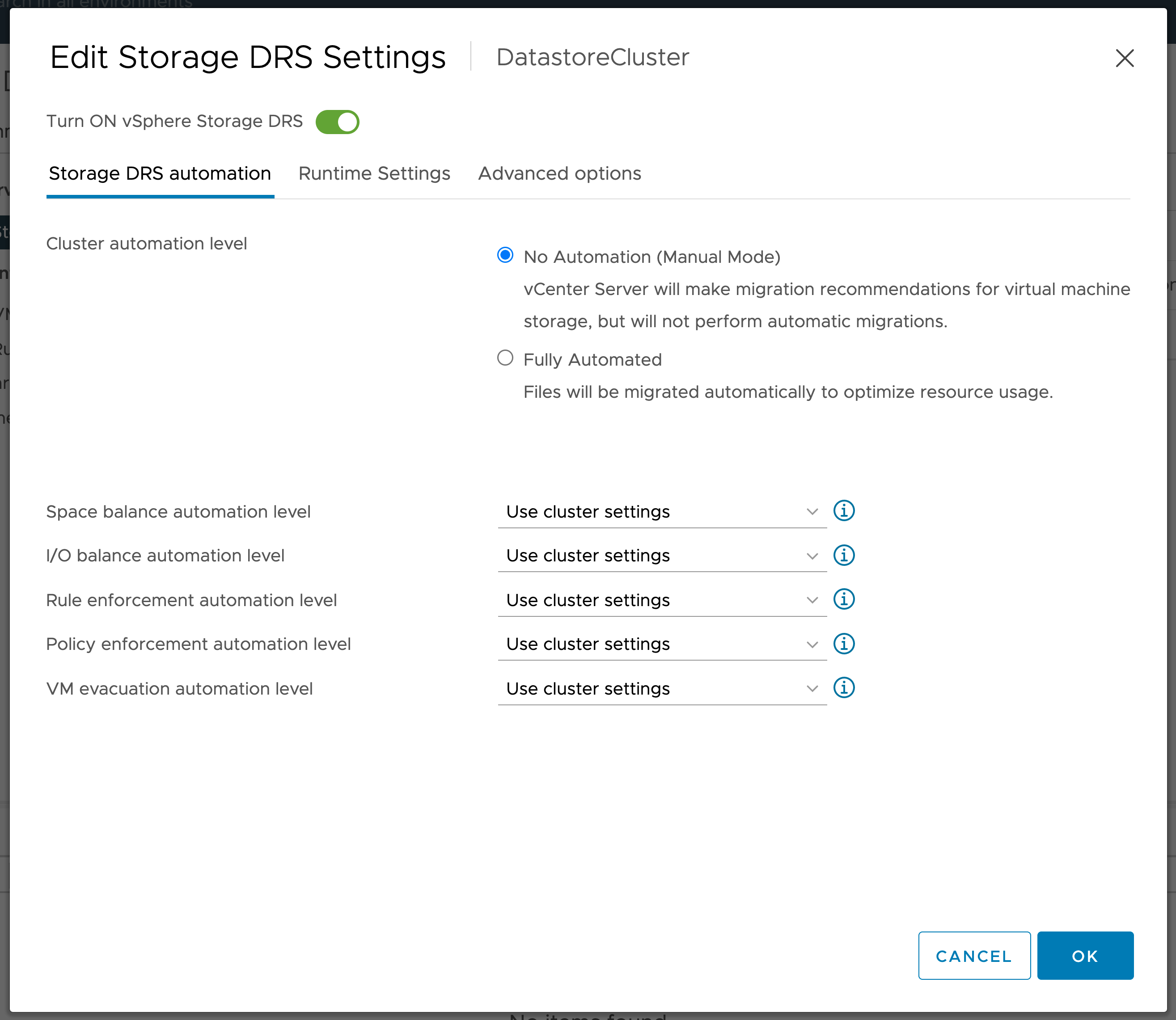
When enabling capacity-based thresholds with Datastore Clusters comprised of Datastores presented from different arrays, choose Manual Mode to prevent unexpected cross array Storage vMotions.
Summary
Datastore Clusters allow vSphere administrators the ability to group several Datastores into a single target for virtual machine deployment. Enabling Storage DRS on Datastore Clusters can give administrators even more control of virtual machine placement, either manually or automatically, to better balance capacity and performance across the grouped Datastores.
With average latencies below that of the Storage DRS performance threshold, using I/O Metrics is not necessary when a Datastore Cluster is backed by PureStorage FlashArray. Capacity utilization however can be used to more evenly distribute used capacity across FlashArray presented Datastores.
It is also important to remember that Datastores in a Datastore Cluster that are presented from the same FlashArray can take advantage of VAAI when moving data from one Datastore to another. The reverse is also true, in that Datastore Clusters with Datastores from multiple arrays cannot take advantage of VAAI.
So plan accordingly!
In Part 2, I’ll cover how Datastore Clusters, Storage DRS, and Storage Policy Based Management can be used to add tiering…
One thought on “VMware StorageDRS on FlashArray Part1- Performance/Capacity Thresholds”